Project 5 (DSC400) | Amazon Reviews Analysis 📦
Analyzing millions of Amazon customer reviews to extract actionable business insights and predict product ratings. This project demonstrates skills in large-scale data processing, feature engineering, statistical analysis, machine learning, and transformer-based NLP modeling. Insights from the project inform product strategy, marketing decisions, and scalable automated review analysis pipeline. 🛒
Links 🔗
GitHub Repo 💻 Project Home Page 🌐 Dashboard 📊Project Overview 📄
This project analyzes ~123GB of Amazon customer review data (subset used: 129,794 reviews) from 58,902 products between 2000–2018. The analysis identifies sentiment patterns, predicts product ratings, and evaluates reviewer behavior using structured features and unstructured review text. Methods include statistical testing, hierarchical machine learning models, and transformer-based NLP with DistilBERT.
Project Workflow 🪜
- NB 1 – Data Ingestion & Cleaning
- NB 2 – Exploratory Data Analysis & Feature Engineering
- NB 3 – Visualization
- NB 3b – Dashboard
- NB 4 – Statistical Analysis
- NB 5 – Machine Learning & NLP Modeling
Visuals 📷
Figure 1. Class Distribution Pie Chart
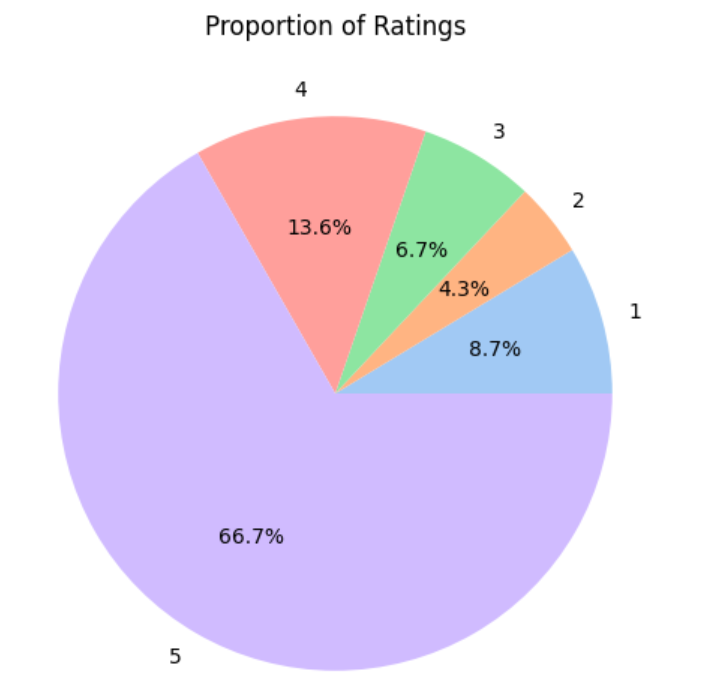
Clear rating imbalance with 5-star reviews dominating the dataset, noted before further phases to address bias.
Figure 2. DistilBERT Training & Validation Metrics
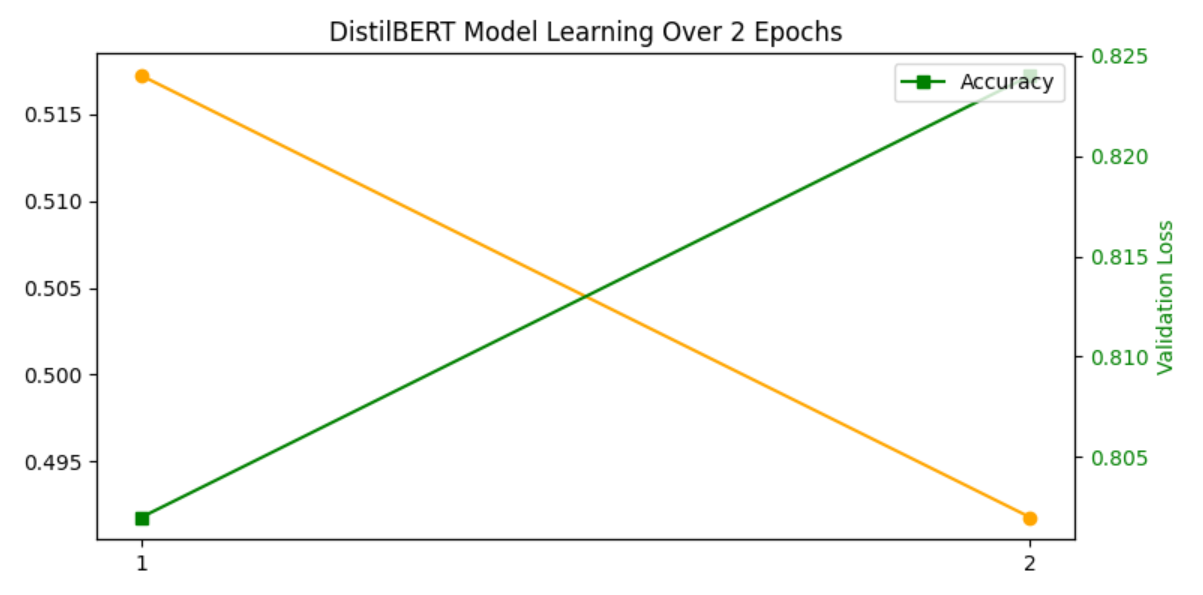
Improving accuracy (green line) and decreasing validation loss (green line) indicate the model was learning effectively without severe overfitting.
Figure 3. Normalized Confusion Matrix
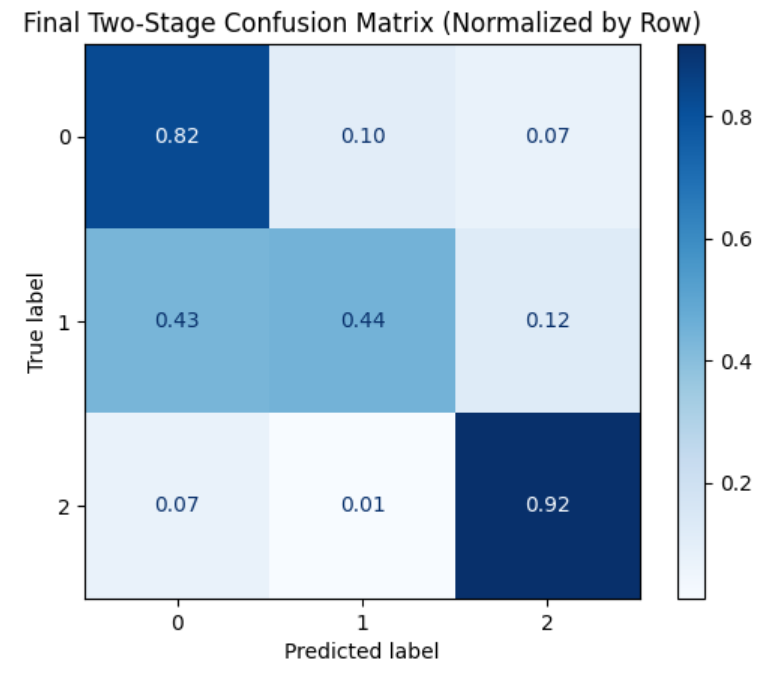
This plot highlights per-class performance by avoiding misleading dominance from the high-rating majority class.
Figure 4. Model Performance Comparison
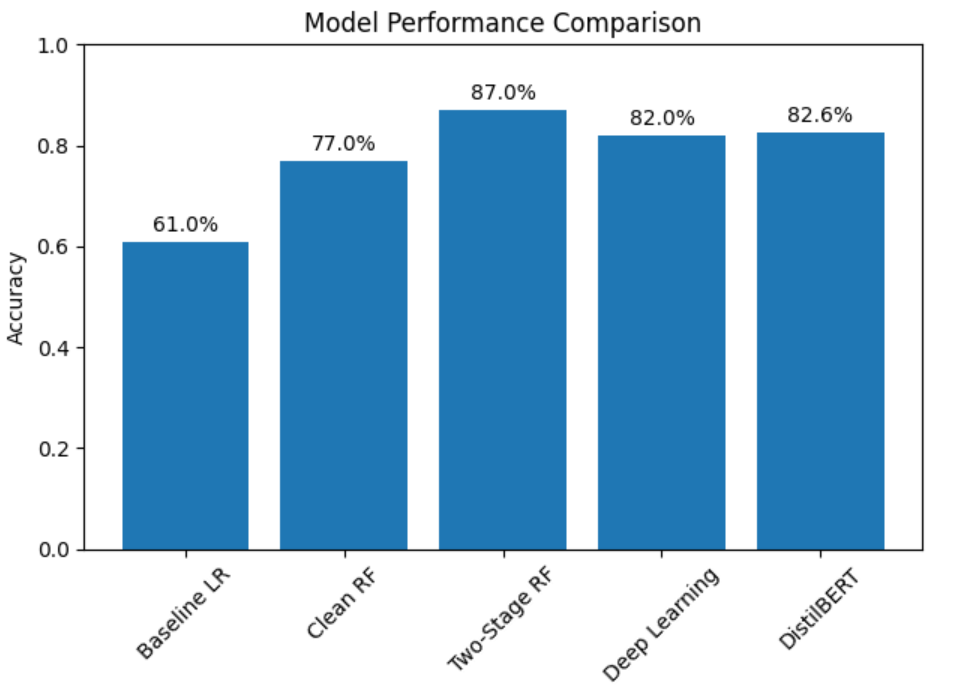
Feature enrichment and leaky feature removal improved Random Forest performance, while the two-stage approach shows the best balance, especially for minority classes.
Key Results 🟰
- 5-star reviews dominate (~66%), causing class imbalance challenges
- Strong correlation between review text sentiment and star rating
- Hierarchical models improved mid-range rating prediction (Macro F1: 0.70)
- Transformer-based NLP (DistilBERT) achieved 82.6% accuracy, showing contextual text modeling benefits
- Verified purchase reviews slightly differ from non-verified reviews
Technical Stack 🔨
Core: Python, Pandas, NumPy, NLTK
Visualization: Matplotlib, Seaborn, Plotly
ML Models: Logistic Regression, Random Forest, Hierarchical Models
NLP: Hugging Face Transformers (DistilBERT)
Evaluation: Accuracy, Macro F1, Precision/Recall, Confusion Matrices
Ethical Considerations ⚖️
- Public dataset only; no personal identifiying information used
- Prevent model bias against low-volume reviewers or products
- Continuous performance monitoring and fairness auditing
- Manual oversight for downstream decision-making